Read a CSV file Using read_csv()
If you know some pandas syntax already, then this will look very familiar to you. Polars has the same syntax to read csv files.
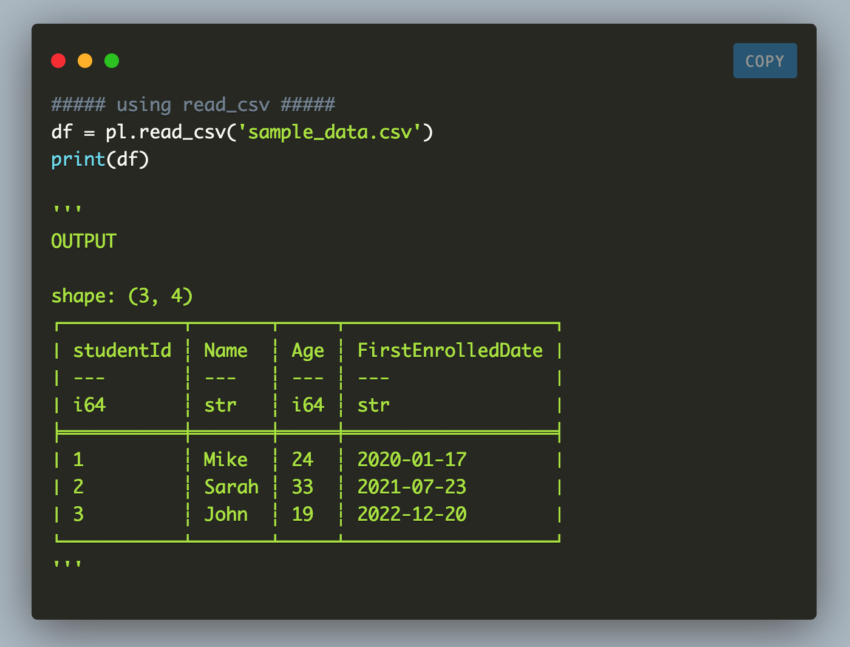
##### using read_csv #####
df = pl.read_csv('sample_data.csv')
print(df)
'''
OUTPUT
shape: (3, 4)
┌───────────┬───────┬─────┬───────────────────┐
│ studentId ┆ Name ┆ Age ┆ FirstEnrolledDate │
│ --- ┆ --- ┆ --- ┆ --- │
│ i64 ┆ str ┆ i64 ┆ str │
╞═══════════╪═══════╪═════╪═══════════════════╡
│ 1 ┆ Mike ┆ 24 ┆ 2020-01-17 │
│ 2 ┆ Sarah ┆ 33 ┆ 2021-07-23 │
│ 3 ┆ John ┆ 19 ┆ 2022-12-20 │
└───────────┴───────┴─────┴───────────────────┘
'''
You can look at the Polars documentation for read_csv() on some of the parameters options. For example, in the code above, notice that the date column has data type of str. But we want it be type of date. You can parse date columns upon reading the file using “parse_dates” parameter:
# with parse_date
df = pl.read_csv('sample_data.csv', parse_dates=True)
print(df)
'''
shape: (3, 4)
┌───────────┬───────┬─────┬───────────────────┐
│ studentId ┆ Name ┆ Age ┆ FirstEnrolledDate │
│ --- ┆ --- ┆ --- ┆ --- │
│ i64 ┆ str ┆ i64 ┆ date │
╞═══════════╪═══════╪═════╪═══════════════════╡
│ 1 ┆ Mike ┆ 24 ┆ 2020-01-17 │
│ 2 ┆ Sarah ┆ 33 ┆ 2021-07-23 │
│ 3 ┆ John ┆ 19 ┆ 2022-12-20 │
└───────────┴───────┴─────┴───────────────────┘
'''
You can add some data manipulations when reading the file as well. Look at the data type of Age column:
# with a new date type for a column
# changing Age column to data type of int32
df = pl.read_csv('sample_data.csv', parse_dates=True).with_columns(pl.col('Age').cast(pl.Int32))
print(df)
'''
shape: (3, 4)
┌───────────┬───────┬─────┬───────────────────┐
│ studentId ┆ Name ┆ Age ┆ FirstEnrolledDate │
│ --- ┆ --- ┆ --- ┆ --- │
│ i64 ┆ str ┆ i32 ┆ date │
╞═══════════╪═══════╪═════╪═══════════════════╡
│ 1 ┆ Mike ┆ 24 ┆ 2020-01-17 │
│ 2 ┆ Sarah ┆ 33 ┆ 2021-07-23 │
│ 3 ┆ John ┆ 19 ┆ 2022-12-20 │
└───────────┴───────┴─────┴───────────────────┘
'''
Another thing that’s not directly related to reading csv is that Polars tells you columns types when you output your dataframe. Pandas doesn’t do this and I honestly love this feature!
Read a CSV file using scan_csv()
scan_csv() is more efficient way to read a csv file. The below is what the documentation says:
This allows the query optimizer to push down predicates and projections to the scan level, thereby potentially reducing memory overhead.
https://pola-rs.github.io/polars/py-polars/html/reference/api/polars.scan_csv.html#polars.scan_csv
That basically means if you’re applying filters or selecting certain columns when reading, then you only get that much data into memory, hence, it’s a more efficient use of resource. It utilizes lazy evaluation where Polars waits on execution until collect() gets called. You can read more on lazy evaluation in the documentation.
And here’s the code to scan and output the csv file into a dataframe:
##### using scan_csv #####
q = pl.scan_csv('sample_data.csv')
print(q.collect())
'''
shape: (3, 4)
┌───────────┬───────┬─────┬───────────────────┐
│ studentId ┆ Name ┆ Age ┆ FirstEnrolledDate │
│ --- ┆ --- ┆ --- ┆ --- │
│ i64 ┆ str ┆ i64 ┆ str │
╞═══════════╪═══════╪═════╪═══════════════════╡
│ 1 ┆ Mike ┆ 24 ┆ 2020-01-17 │
│ 2 ┆ Sarah ┆ 33 ┆ 2021-07-23 │
│ 3 ┆ John ┆ 19 ┆ 2022-12-20 │
└───────────┴───────┴─────┴───────────────────┘
'''
If you don’t call collect(), you’ll only get this output showing it contains lazy dataframe:
q = pl.scan_csv('sample_data.csv')
print(q)
'''
naive plan: (run LazyFrame.describe_optimized_plan() to see the optimized plan)
CSV SCAN sample_data.csv
PROJECT */4 COLUMNS
'''
Source code: Github repo