

This article is about an unofficial benchmark on DuckDB and Polars. Updated with new versions of libraries. They’re noted in red.
Motivation
Who doesn’t like benchmarking? Especially in the data industry, new tools are emerging every year and existing tools are becoming more powerful, you can’t get more excited about seeing and experiencing the improved performance of data tools.
In fact, I did a benchmark on pandas vs Polars a while ago. It was so fun and many other folks also seemed to have enjoyed seeing the performance comparison between pandas and Polars. But this time, I decided to do a benchmark on DuckDB and Polars.
At least several benchmarks are already done comparing DuckDB and Polars, but if you’re nerdy enough about data tech, you have to do it on your own. This article shows my benchmark between DuckDB and Polars. And just for your reference, I listed other benchmarks I’m aware of at the end of this article.
If there are other benchmarks out there, what’s unique about this benchmark? This benchmark uses a dataset that’s not too crazy and probably about the size you may work with in your day-to-day work. And I came up with simple and not too complex of queries. More importantly, I’m doing this benchmarking for my own sake!
You can find the source code used for the benchmark in this GitHub repo.
Setup
We’re using 2021 Yellow Taxi Trip which contains 30M rows with 18 columns. It’s about 3GB in size on disk. The benchmark is done on my laptop, which is an Apple M1 MAX MacBook Pro 2021 with 64GB RAM, 1TB SSD, and a 10-core CPU.
I’m using duckdb==0.10.0 and polars==0.20.15. Updates: now these versions have been updated for this benchmark. duckdb==1.0.0 and polars==0.20.31
I made the code structure similar to that of Marc Garcia’s benchmark, just because I liked how easy it was to understand his code and the structure.
Method
We execute the following operations:
- Reading a CSV file
- Simple aggregations (sum, mean, min, max)
- Groupby aggregations
- Window functions
- Joins
The following is the source code for each query:
- Reading a CSV file – DuckDB (read_csv_duckdb.py)
import duckdb
def read_csv_duckdb(file_path):
query = f'''
select * from "{file_path}";
'''
return duckdb.sql(query).arrow()
if __name__ == '__main__':
print(read_csv_duckdb('data/2021_Yellow_Taxi_Trip_Data.csv'))
- Reading a CSV file – Polars (read_csv_polars.py)
import polars as pl
def read_csv_polars(file_path):
lf = pl.scan_csv(file_path)
return lf.collect()
if __name__ == '__main__':
print(read_csv_polars('data/2021_Yellow_Taxi_Trip_Data.csv'))
- Simple aggregations (sum, mean, min, max) – DuckDB (agg_duckdb.py)
import duckdb
def agg_duckdb(file_path):
query = f'''
select
sum(total_amount),
avg(total_amount),
min(total_amount),
max(total_amount)
from "{file_path}"
;
'''
return duckdb.sql(query).arrow()
if __name__ == '__main__':
print(agg_duckdb('data/2021_Yellow_Taxi_Trip_Data.csv'))
- Simple aggregations (sum, mean, min, max) – Polars (agg_polars.py)
import polars as pl
def agg_polars(file_path):
lf = pl.scan_csv(file_path)
return (
lf
.select(
sum=pl.col('total_amount').sum(),
avg=pl.col('total_amount').mean(),
min=pl.col('total_amount').min(),
max=pl.col('total_amount').max()
)
.collect()
)
if __name__ == '__main__':
print(agg_polars('data/2021_Yellow_Taxi_Trip_Data.csv'))
- Groupby aggregations – DuckDB (groupby_agg_duckdb.py)
import duckdb
def groupby_agg_duckdb(file_path):
query = f'''
select
VendorID,
payment_type,
sum(total_amount),
avg(total_amount),
min(total_amount),
max(total_amount)
from "{file_path}"
group by
VendorID,
payment_type
;
'''
return duckdb.sql(query).arrow()
if __name__ == '__main__':
print(groupby_agg_duckdb('data/2021_Yellow_Taxi_Trip_Data.csv'))
- Groupby aggregations – Polars (grouopby_agg_polars.py)
import polars as pl
def groupby_agg_polars(file_path):
lf = pl.scan_csv(file_path)
return (
lf
.group_by('VendorID', 'payment_type')
.agg(
sum=pl.col('total_amount').sum(),
avg=pl.col('total_amount').mean(),
min=pl.col('total_amount').min(),
max=pl.col('total_amount').max()
)
.collect()
)
if __name__ == '__main__':
print(groupby_agg_polars('data/2021_Yellow_Taxi_Trip_Data.csv'))
- Window functions – DuckDB (window_func_duckdb.py)
import duckdb
def window_func_duckdb(file_path):
query = f'''
select
avg(fare_amount) over(partition by VendorID),
dense_rank() over(partition by payment_type order by total_amount desc)
from "{file_path}"
;
'''
return duckdb.sql(query).arrow()
if __name__ == '__main__':
print(window_func_duckdb('data/2021_Yellow_Taxi_Trip_Data.csv'))
- Window functions – Polars (window_func_polars.py)
import polars as pl
def window_func_polars(file_path):
lf = pl.scan_csv(file_path)
return (
lf
.select(
avg_fare_per_vendor=pl.col('fare_amount').mean().over('VendorID'),
ttl_amt_rank_per_pay_type=pl.col('total_amount').rank(method='dense', descending=True).over('payment_type')
)
.collect()
)
if __name__ == '__main__':
print(window_func_polars('data/2021_Yellow_Taxi_Trip_Data.csv'))
- Joins – DuckDB (join_duckdb.py)
import duckdb
def join_duckdb(file_path):
query = f'''
with base as (
select
*,
month(tpep_pickup_datetime) pickup_month,
from "{file_path}"
),
join_data as (
select
VendorID,
payment_type,
pickup_month,
sum(total_amount)
from base
group by
VendorID,
payment_type,
pickup_month
)
select *
from base
inner join join_data
using (VendorID, payment_type, pickup_month)
;
'''
return duckdb.sql(query).arrow()
if __name__ == '__main__':
print(join_duckdb('data/2021_Yellow_Taxi_Trip_Data.csv'))
- Joins – Polars (join_polars.py)
import polars as pl
def join_polars(file_path):
base_lf = (
pl.scan_csv(file_path)
.with_columns(
pl.col('tpep_pickup_datetime').str.to_datetime('%m/%d/%Y %I:%M:%S %p')
.dt.month()
.alias('pickup_month')
)
)
join_lf = (
base_lf
.group_by('VendorID', 'payment_type', 'pickup_month')
.agg(
sum=pl.col('total_amount').sum()
)
)
return (
base_lf
.join(
join_lf,
on=['VendorID', 'payment_type', 'pickup_month'],
how='inner'
)
.collect()
)
if __name__ == '__main__':
print(join_polars('data/2021_Yellow_Taxi_Trip_Data.csv'))
Result
Here’s the result of the benchmark:
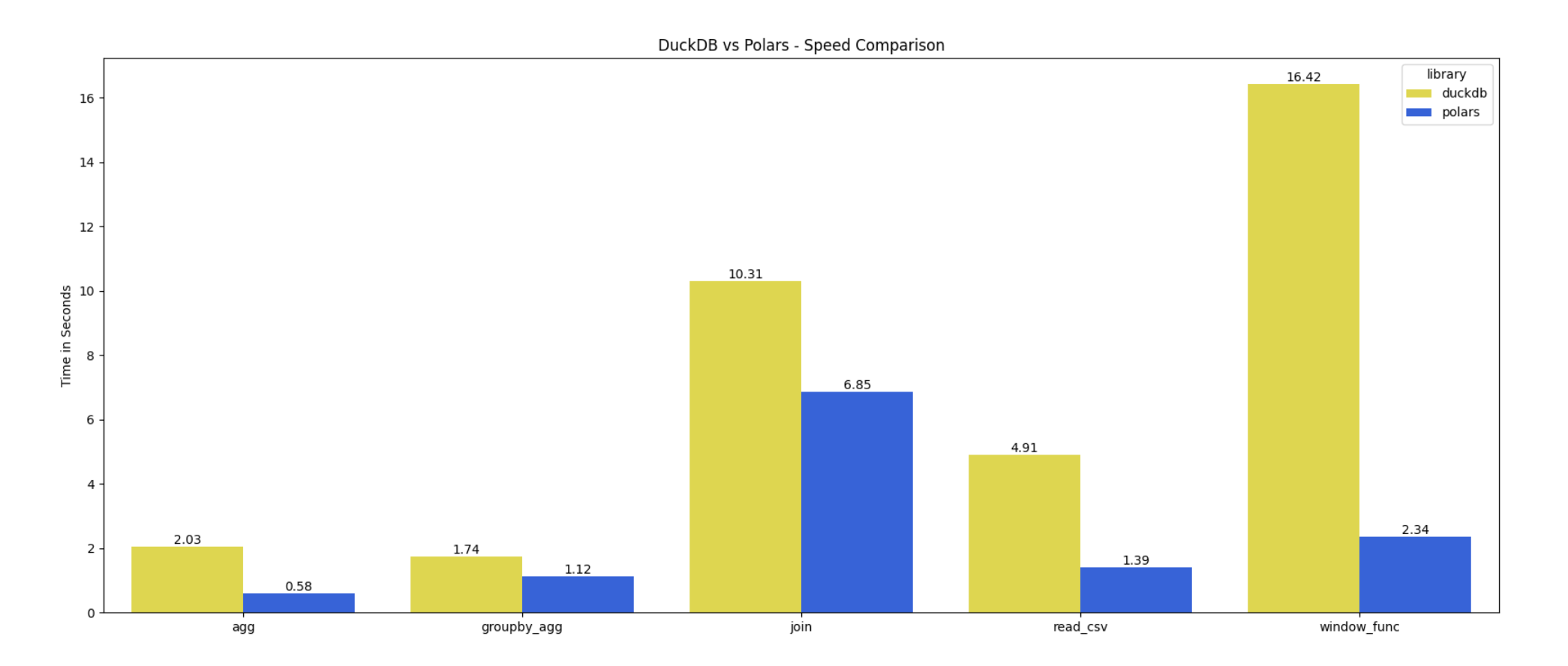
I was actually surprised by the result. My initial expectation was that DuckDB might win for most of the queries. But the result tells me otherwise. And the differences between reading the CSV file and window functions are pretty large.
Polars is 3x faster for reading the CSV file and more than 7x faster for executing the window functions. I know Polars has a very fast CSV reader, but I didn’t expect this big of a difference for the window functions. Maybe those specific window functions I came up with were hard to process for DuckDB? Who knows.
For the join operation, DuckDB was about 1.3x faster than Polars. I’m curious how this changes when joining with large datasets. Joins are an expensive operation, but it’s crucial, especially for analytics workloads that require data integration and consolidation.
Updates: With the new versions of DuckDB and Polars, Polars outperformed in all queries. Even for the join operation that DuckDB previously outperformed, now Polars is faster than DuckDB.
How to Run This Benchmark on Your Own
Here are the step-by-step instructions for how to reproduce the benchmark on your own:
1. Download the CSV file at 2021 Yellow Taxi Trip.
2. Create data folder at the top level in the repo and place the CSV file in the folder. The path of the file should be: data/2021_Yellow_Taxi_Trip_Data.csv. If you name it differently then you’ll need to adjust the file path in the Python script(s).
3. Make sure you’re in the virtual environment.
$ python -m venv env
$ source env/bin/activate
4. Install dependencies.
$ pip install -r requirements.txt
Or
$ pip install duckdb polars pyarrow pytest seaborn
5. Run the benchmark.
$ python duckdb_vs_polars
Optional: Run the following command in the terminal to run unit tests.
$ pytest
Notes/Limitations
- All the queries used for the benchmark are created by Yuki (blog author). If you think they can be improved or want to add other queries for the benchmark, please feel free to make your own or make a pull request.
- Benchmarking DuckDB queries is tricky because result collecting methods such as
.arrow(),.pl(),.df(), and.fetchall()in DuckDB can make sure the full query gets executed, but it also dilutes the benchmark because then non-core systems are being mixed in..arrow()is used to materialize the query results for the benchmark. It was the fastest out of.arrow(),.pl(),.df(), and.fetchall()(in the order of speed for the benchmark queries).- You could argue that you could use
.execute(), but it might not properly reflect the full execution time because the final pipeline won’t get executed until a result collecting method is called. Refer to the discussion on DuckDB discord on this topic. - Polars has the
.collect()method that materializes a full dataframe.
Conclusion
What did you think of the result? Was it surprising or expected? I’m typically biased towards Polars for anything just because I enjoy working with it or I’m writing a book on it, but in this benchmark, I tried to play as fair as I could. I found the performance was very similar in both tools.
All in all, one thing I can say for sure is that both DuckDB and Polars are blazingly fast. You can’t go wrong if you pick one of them for your project. Hope this helps you gain insights on the performance difference between DuckDB and Polars. Or at least, I hope you enjoyed reading this article!
If you enjoyed this post or have suggestions, feel free to connect with/contact me on LinkedIn or email me at yuki@stuffbyyuki.com. Also, please feel free to reach out if you’d like to discuss how I can help your company with related work.
Resources
Here’s a list of benchmarks I’m aware of that compare DuckDB and Polars: